

امروزه ابزارهای هوش مصنوعی تبدیل متن به صدا طرفداران زیادی دارد. چرا که ضبط صدا به تنهایی فرایندی دشوار و زمانبر است. برای دستیابی به نتیجهای رضایتبخش، اغلب نیاز می شود برداشتهای متعددی انجام دهید. همچنین احتمالا برای تمرین و رسیدن به لحن و هدف دلخواه فرصت کافی در اختیار ندارید و مطالعه راهنماهای طولانی مربوط به نرمافزارهای ویرایش صدا نیز برای اطمینان از کیفیت خروجی لازم است. حتی با انجام صحیح تمام مراحل، عدم دسترسی به یک استودیوی حرفهای میتواند در اجرای بینقص شما نویز ایجاد کند.
شاید در چنین شرایطی به استخدام یک صداپیشه حرفهای فکر کنید اما امروزه مولدهای صوتی مبتنی بر هوش مصنوعی می توانند این کار را برایتان انجام دهند و نتایجی چشمگیر ارائه کنند. این ابزارهای تبدیل متن به گفتار با پیشرفتهایی که در زمینه کیفیت، واقعگرایی و سطح کنترل داشته اند، به شما امکان میدهند تا بدون میکروفون یا تجهیزات حرفهای، صدایی طبیعی و دقیق از متن موردنظرتان داشته باشید.

تصویر(1)
چه چیزی بهترین هوش مصنوعی تبدیل متن به صدا را میسازد؟
بهترین هوش مصنوعی تبدیل متن به صدا به راحتی قابل شناسایی هستند. صدای تولید شده طبیعی و واقعی به نظر میرسد، گویی انسانی واقعی در حال ادای کلمات است.
برای افرادی که قصد دارند به طور کامل از صدای هوش مصنوعی استفاده کنند، امکان یادگیری زبان نشانهگذاری ترکیب گفتار (SSML یا Speech Synthesis Markup Language) نیز وجود دارد. این زبان اجازه میدهد تا هر کلمه با بیشترین سطح کنترل و دقت اجرا گردد. در عین حال، نباید در استفاده از این قابلیت افراطی عمل شود زیرا ممکن است به کاهش کیفیت و غیر طبیعیبودن خروجی منجر گردد.
با در نظر داشتن این نکات، جهت ارزیابی ابزارهای هوش مصنوعی تبدیل متن به صدا، معیارهای زیر مدنظر قرار گرفته اند:
۱. واقعگرایی: برنامههای تبدیل متن به صدا باید گفتاری طبیعی و متنوع با تغییرات ظریف در لحن گفتار و مکثهای به موقع ارائه دهند.
۲. کنترلهای موجود: وجود قابلیتهایی مانند تنظیم زیر و بم صدا، سرعت خواندن و نحوه تلفظ، امکان سفارشیسازی خروجی را بر اساس نیازهای کاربر فراهم میکند.
۳. کیفیت صدا: بالاترین سطح کیفیت مورد انتظار است تا بتوان از آن در پروژههای حرفهای بهره برد.
۴. تنوع صدا: دسترسی به کتابخانهای گسترده از صداهای مختلف، خصوصا صداهایی در زبانهای گوناگون، موجب انعطافپذیری بیشتر جهت کاربردهای مختلف میشود.
۵. امکانات اضافی: در صورتی که یک برنامه امکانات پیشرفتهتری نظیر تبدیل صدا یا امکان آموزش مدل هوش مصنوعی را ارائه دهد، در این ارزیابی لحاظ شدهاند. البته ابزارهای تولید ویدیو حتی اگر دارای ویژگی تبدیل متن به صدا نیز بودند، در این مقاله مورد بررسی قرار نگرفتهاند.
در تهیه این مقاله، صرفاً به آزمون فنی بسنده نشده و جنبه های ظریفتری از کیفیت صدا نیز مورد بررسی قرار گرفته اند. از جمله این موارد:
- سرعت روایت: انسانها هنگام خواندن متن، در سرعت گفتار تنوع ایجاد میکنند که به تأکید بیشتر و افزایش جذابیت کمک میکند. مدلهای ضعیف هوش مصنوعی اغلب دارای سرعتی یکنواخت هستند، در حالی که مدلهای برتر این تنوع را حفظ میکنند.
- آهنگ صدا (Intonation): آهنگ صدا به تغییرات زیر و بم در طول جمله اشاره دارد. مدلهایی که لحن یکنواخت و قابل پیشبینی ارائه میدهند، حالتی رباتگونه و غیرانسانی پیدا میکنند.
- اجرای احساسی: برخی از برنامهها امکان انتخاب لحنهایی مانند غمگین، هیجانزده یا زمزمهمانند را فراهم میکنند اما اگر این اجرای احساسی فاقد ظرافت لازم باشد از فهرست حذف میشود. با این حال، باید توجه داشت که اجرای احساسی دقیق هنوز هم چالشی برای هوش مصنوعی محسوب میشود.
طی این بررسی یک متن یکسان در تمام پلتفرمها استفاده شد تا بتوان تفاوتها را با دقت مقایسه کرد.
1. ElevenLabs: پیشرفتهترین هوش مصنوعی تبدیل متن به صدا با صدها صدای واقعگرایانه
تصویر(2)
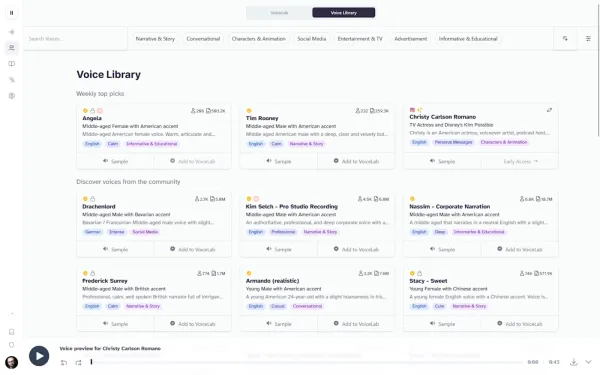
پلتفرم ElevenLabs یکی از پیشتازان حوزه تولید صدای هوش مصنوعی به شمار میآید و با کتابخانهای گسترده که بیش از ۳۰۰ صدای متنوع را شامل میشود، جایگاه ویژهای در میان رقبا یافته است.
با این تنوع گسترده، وجود ابزارهای جستجو و فیلتر کارآمد در آن کاملاً ضروری بوده و خوشبختانه ElevenLabs در این زمینه نیز عملکردی قابل تحسین دارد. کاربران با کلیک بر گزینه Voices در منوی سمت چپ و انتخاب تب Voice Library از بالای صفحه، میتوانند به فهرست صداها دسترسی پیدا کنند.
برای جستجوی هدفمندتر، دستهبندیهایی نیز در نظر گرفته شدهاند که امکان فیلتر صداها براساس سبک و کاربرد را فراهم میکنند؛ از صداهای محاورهای گرفته تا صدای گویندگان تبلیغاتی، پلتفرم ElevenLabs تلاش کرده برای هر نوع پروژهای گزینهای در اختیار کاربر قرار دهد.
در سمت راست این دستهبندیها، قابلیت مرتبسازی براساس چهار ویژگی مختلف فراهم شده است؛ از صداهای محبوب گرفته تا آنهایی که خروجیهای صوتی بیشتری تولید کردهاند. افزون بر این، فیلترهای پیشرفتهتری نیز وجود دارند که کاربران را قادر میسازند صداها را بر اساس ویژگیهایی همچون دستهبندی، جنسیت، سن، زبان و لهجه فیلتر کنند.
هنگامی که کاربر صدایی مناسب یافت، میتواند آن را به بخش Voice Lab اضافه کند. این بخش، امکان استفاده از صدای انتخابی در خروجی نهایی گفتار را فراهم میسازد. بدین منظور کافی است به بخش Speech مراجعه شود و با آپلود متن موردنظر یا فایل صوتی و همچنین انتخاب صدای موردنظر، گزینه Generate انتخاب شود.
در صورتی که نتیجه اولیه رضایتبخش نباشد دو گزینه برای بهینهسازی در اختیار کاربر قرار دارد:
۱. انتخاب مدل هوش مصنوعی متفاوت: هر مدل عملکرد منحصر به فردی دارد. به عنوان نمونه، برخی مدلها برای تولید صدای چندزبانه بهتر طراحی شدهاند اما برخی دیگر در کاهش تاخیر (Latency) برتری دارند.
ElevenLabs که در حال حاضر با مبلغی معادل یک میلیارد دلار ارزشگذاری شده، منابع مالی کافی برای توسعه بیشتر در اختیار دارد. این پلتفرم با وجود اینکه در برخی زمینهها کنترلهای کمتری نسبت به رقبا ارائه می دهد، همچنان یکی از قدرتمندترین گزینهها به شمار میرود.
مدل قیمتگذاری هوش مصنوعی تبدیل متن به گفتار ElevenLabs:
پلن پایه رایگان، حدود ۱۰ دقیقه تولید صدا در ماه را شامل میشود. پلن های پولی از ۵ دلار در ماه (یا ۵۰ دلار سالانه) آغاز میشوند و امکانات بیشتری نظیر شبیهسازی صدا (Voice Cloning) را نیز ارائه میدهند.
2. Speechify: بهترین هوش مصنوعی تبدیل متن به صدا از نظر ریتم طبیعی و انسانگونه
تصویر(3)
ریتم هنگام خواندن متن، به فواصل زمانی بین واژهها و سرعت کلی اجرای متن اشاره دارد که نقش تعیینکنندهای در طبیعی بودن گفتار ایفا میکند. در این زمینه، هوش مصنوعی تبدیل متن به صدای Speechify عملکردی فراتر از رقبا نشان داده و قادر است تنها با یک بار تولید، خروجی گوشنواز و حرفهای ارائه دهد، همانطور که از یک گوینده باتجربه و خلاق انتظار میرود. این خروجی با سرعتی متعادل، لحن ملایم و هماهنگی مطلوب بین یکنواختی و تنوع، تولید میشود.
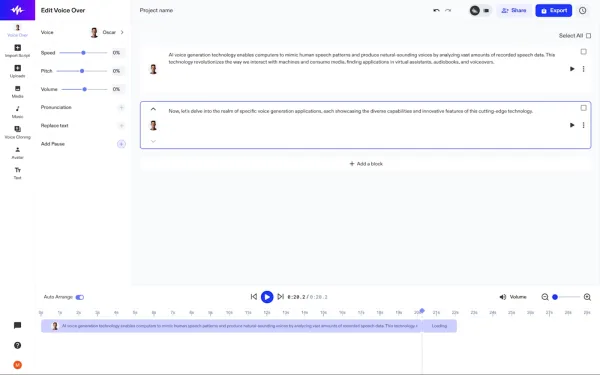
نکته جالب درمورد هوش مصنوعی تبدیل متن به صدای Speechify، بهرهگیری از صداهای معروفی مانند «اسنوپ داگ» و «گوئینت پالترو» در این ابزار می باشد که تجربه شنیدن محتوای متنی مانند پستهای وبلاگی یا مطالب آموزشی را جذابتر میکند. با این حال، در بخش تولید محتوا برای پروژههای شخصی و حرفهای، کاربران باید به بخش Speechify Studio مراجعه کنند که با کلیک روی دکمهای در بالای صفحه قابل دسترسی است.
در بخش Studio این ابزار تولید صدای هوش مصنوعی، اگرچه امکان استفاده از صداهای مشهور وجود ندارد اما گزینههای صوتی موجود از کیفیت بالایی برخوردار هستند. کاربران با وارد کردن فیلمنامه خود در این بخش میتوانند مجموعهای از تنظیمات حرفهای را مشاهده کنند، مانند:
- تنظیم سرعت اجرای متن
- کنترل زیر و بم صدا
- تغییر حجم صدا
- افزودن تلفظهای سفارشی برای کلمات خاص
- تنظیم مکثهای دقیق در بخشهای دلخواه متن
علاوه بر این امکانات اصلی، ابزار تولید صدای هوش مصنوعی Speechify دو ویژگی جانبی ارزشمند نیز ارائه میدهد:
- تولید ارائههای ساده و سریع بر پایه صدا: برای کاربرانی که تولید ویدیوهای مبتنی بر اسلاید را انجام می دهند،هوش مصنوعی تبدیل متن به صدای Speechify ابزاری را فراهم کرده که به سادگی با تولید صدا، افزودن موسیقی پسزمینه و ایجاد خروجی نهایی، یک ارائه منسجم و قابلاستفاده تولید میکند.
- افزودن صدای کاربر به پلتفرم: کاربران میتوانند صدای خود را به سیستم معرفی کنند و از آن پس، محتوای متنی را توسط صدای شخصی خود به گفتار تبدیل نمایند.
مدل قیمتگذاری ابزار تولید صدای هوش مصنوعی Speechify:
نسخه پایه این پلتفرم رایگان است اما امکان دانلود خروجی صوتی در آن وجود ندارد. پلن های پولی از ۲۴ دلار در ماه به ازای هر کاربر (با صورتحساب سالانه) آغاز میشود و در صورت پرداخت ماهانه، هزینه آن به ۶۹ دلار افزایش مییابد.
3. WellSaid Labs: بهترین مولد صدای هوش مصنوعی برای کنترل دقیق و کلمه به کلمه
تصویر(4)
در حالی که بسیاری از ابزارهای هوش مصنوعی تبدیل متن به صدا تنها تنظیمات کلی و عمومی روی خروجی را ارائه میدهند، WellSaid Labs امکان مدیریت دقیق و موشکافانهای را حتی در سطح کلمه به کلمه، ارائه می کند.
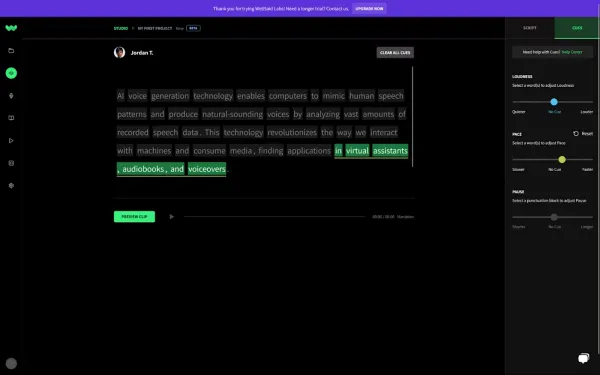
برای کار با نرم افزار تبدیل متن به گفتار WellSaid Labs کافی است ویرایشگر اصلی را باز کرده و فیلمنامه موردنظر خود را وارد کنید. سپس از طریق تب سمت راست روی گزینه Cues کلیک نمایید تا تنظیمات در دسترس قرار گیرند. هر کلمه روی صفحه به صورت جداگانه مشخص شده است. با کلیک روی یک کلمه یا ترکیبی از کلمات، میتوانید ویژگیهایی مانند میزان صدا (Volume) یا سرعت خواندن (Speed) را تنظیم نمایید. همچنین، انتخاب علائم نگارشی مانند ویرگول یا نقطه به شما این امکان را میدهد که مدت زمان مکث پس از آن بخش خاص را به صورت سفارشی مشخص کنید.
پس از ویرایش یک بخش، با کلیک روی هر نقطه خالی در مرکز صفحه، انتخاب خود را لغو نمایید. در این مرحله، تغییرات اعمالشده به صورت رنگی زیرخطدار ظاهر خواهند شد:
- سبز: تغییرات مربوط به سرعت
- آبی: تنظیمات میزان صدا
- بنفش: کنترل مکثها بر اساس علائم نگارشی
این رنگبندی، راهنمایی بصری مناسبی برای بازبینی سریع و اصلاحات بعدی فراهم میسازد. توصیه میشود از تغییرات زیاد پرهیز کنید زیرا نوسانات بیش از حد میتواند به کاهش واقعگرایی صدای نهایی منجر شود.
برخلاف سایر تنظیمات، کنترل تلفظ ها در ویرایشگر تولید صدا قرار ندارد. برای دسترسی به آن، لازم است از منوی سمت چپ روی گزینه Pronunciation کلیک کنید. در این بخش میتوانید برای هر کلمه یک تلفظ جایگزین تعریف نمایید. کافی است کلمه اصلی را وارد کرده و سپس نسخه تلفظ موردنظر خود را تعیین کنید. این فرآیند نیازمند آزمون و خطا بوده و بهتر است از راهنمای بازنویسی و مستندات موجود استفاده نمایید.
برای بهرهگیری حداکثری از امکانات پلتفرم، WellSaid Labs بخشی به نام منابع (Resources) ارائه میدهد که شامل راهنماهای مرحله به مرحله برای شروع کار، بهینهسازی نحوه تولید صدا و تنظیم تلفظ ها است. اگر با دیگران همکاری میکنید، امکان اشتراکگذاری سریع لینک پروژه برای دریافت بازخورد نیز فراهم شده است.
مدل قیمتگذاری هوش مصنوعی تبدیل متن به صدا WellSaid Labs:
نسخه آزمایشی رایگان در دسترس است. پلن های حرفهای از ۴۴ دلار در ماه (با پرداخت سالانه) یا ۴۹ دلار (با پرداخت ماهانه) شروع میشوند.
4. Respeecher: بهترین مولد صدای هوش مصنوعی برای تولید گفتار با تنوع بالا و خلاقانه
تصویر(5)
اگر از خروجیهای یکنواخت و رباتی برخی ابزارهای هوش مصنوعی خسته شدهاید، هوش مصنوعی تبدیل متن به گفتار Respeecher راهحلی نوآورانه و خلاقانه برای افزودن تنوع و جذابیت به تولیدات صوتی ارائه میدهد.
این ابزار هوش مصنوعی تبدیل متن به صدا، با طراحی منحصربه فرد خود، بر ارائه تنوع گفتاری و روایی تمرکز دارد؛ طوری که هر صدای تولید شده طبیعیتر، انسانیتر و شنیدنیتر به نظر برسد. ویژگی ممتاز Respeecher این است که کاربران برای این سطح از تنوع، نیازی به مهندسی دقیق یا مهارت فنی بالا ندارند. تنها با وارد کردن متن، میتوان صدا را در قالب یا سبکهای مختلف تولید کرد.
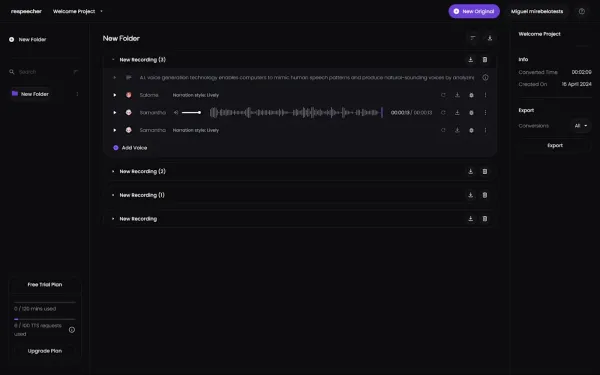
رابط کاربری Respeecher ممکن است در نگاه اول کمی گیجکننده به نظر برسد زیرا تنظیمات پیشرفته تولید صوت در بخش هایی پنهان از صفحه اصلی قرار گرفتهاند. برای دسترسی به آنها، کافی است روی تب Settings در سمت چپ کلیک کنید. در این بخش، میتوان ویژگیهایی نظیر زیر و بم (Pitch)، میزان احساسی بودن (Emotional Range) و ویژگیهای عمومی صدا را تنظیم کرد. لازم به ذکر است که این تنظیمات، بر تمامی خروجیهای آتی تأثیرگذار خواهند بود؛ بنابراین، در صورت نیاز به تنوع یا سبک متفاوت، باید وارد این بخش شد و مجدد تنظیمات را اصلاح کرد.
علاوه بر متن یا فایل صوتی، هوش مصنوعی تبدیل متن به صدای Respeecher این امکان را فراهم میسازد که مستقیماً توسط میکروفون، صدای زنده را ضبط نمایید و در همان لحظه، آن را با الگوی صدای انتخابشده تطبیق دهید. این ویژگی به شما اجازه میدهد اجرای متن را به صورت کامل در اختیار داشته باشید. اگر سابقه بازیگری صوتی یا استعداد طبیعی در فن بیان و لحن دارید، این قابلیت میتواند تجربه ای بسیار خلاقانه و شخصیسازیشده برایتان فراهم آورد.
همچنین هوش مصنوعی تبدیل متن به صدا Respeecher به کاربران امکان میدهد تا مدل هوش مصنوعی را با صدای خود یا دیگران آموزش دهند. این قابلیت، مسیر را برای خلق مجموعهای از شخصیتهای صوتی متنوع هموار میسازد، به گونهای که بتوانید تنها با استفاده از کیبورد، اجرای یک نمایش کامل صوتی را مدیریت کنید. با توجه به پتانسیل سوءاستفاده از این فناوری (نظیر تولید دیپفیک صوتی)، پلتفرم Respeecher یک فرآیند احراز هویت و بررسی امنیتی برای کاربران در نظر گرفته است که همین موضوع، بخشی از هزینه بالاتر اشتراک را توجیه میکند.
بر اساس تجربیات آزمایشی، Respeecher فضای خلاقانهتری نسبت به سایر پلتفرمها دارد. نوع تلفظ، تن صدا و سبک بیان آن به ویژه برای پروژههای کارتونی، ویدیوهای سرگرمی یا سناریوهای غیررسمیتر مناسبتر می باشد. البته این به معنای ناتوانی در کاربردهای رسمی یا تجاری نیست اما ممکن است برای کاربرانی که به دنبال آواتار صوتی حرفهایتر، با حداقل افکتگذاری هستند، کاملاً ایدهآل نباشد. این ویژگی را میتوان به عنوان یک نقطه ضعف یا مزیت رقابتی تفسیر کرد.
مدل قیمتگذاری Respeecher:
اشتراکها از ۴ دلار در ماه آغاز میشوند. البته با توجه به امکانات و کاربردهای پیشرفتهتر، هزینهها میتوانند افزایش قابلتوجهی داشته باشند.
5. Altered: بهترین مولد صدای هوش مصنوعی از لحاظ تنوع در سبک روایت
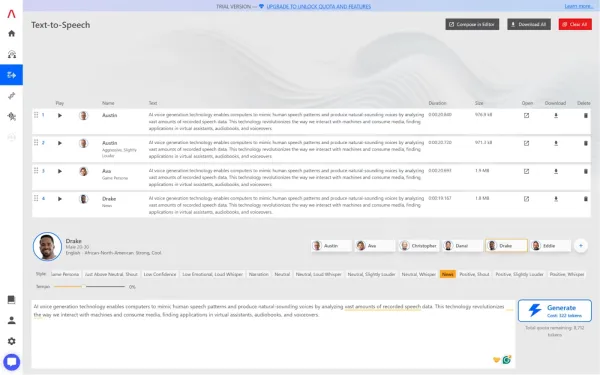
تصویر(6)
در حوزه تولید گفتار با هوش مصنوعی، یکی از مؤلفههای کلیدی که تفاوت میان صدایی معمولی و اجرایی حرفهای را رقم میزند، سبک روایت (Narration Style) است. این ویژگی ترکیبی از ریتم، زیر و بم صدا و تن احساسی می باشد. میان پلتفرمهای موجود، Altered بیشترین گستردگی گزینهها در زمینه سبک روایت را ارائه میدهد و از این جهت در صدر انتخابها برای شخصیسازی بیان قرار دارد. با این حال، پیچیدگی ابزارهای ارائهشده، به گونهای می باشد که کاربران تازهکار، جهت آشنایی کامل با امکانات آن نیاز به صرف زمان بیشتری خواهند داشت.
-
Real-time morphing: قابلیت Real-time morphing به Altered اجازه می دهد تا صدای کاربر را همزمان به صدای یک آواتار هوش مصنوعی تبدیل کند. این قابلیت میتواند در موقعیتهای سرگرمکننده (مانند گفتگوی آنلاین گیمرها) کاربرد داشته باشد اما مزیت مهم آن برای کاربران حرفهای، امکان استفاده مستقیم در محیطهای ویرایش صوتی (مثل Adobe Audition یا Audacity) و سادهسازی روال کاری پروژههای تولید محتوا است.
-
تغییر شکل پس از تولید (Post-production Voice Conversion): این قابلیت که در اصطلاح به آن Voice-to-Voice نیز گفته میشود، به کاربران اجازه میدهد تا یک فایل صوتی ضبط شده را بارگذاری کرده، صدای هدف (Target Voice) را انتخاب کنند و نسخه جدید با صدای جایگزین را تولید نمایند. پس از اتمام پردازش، خروجی صوتی آماده برای دانلود و استفاده در پروژه خواهد بود.
-
ایجاد سریع صدا (Instant Voice Creation): این ابزار به کاربران امکان میدهد که کلیپهایی بین ۴ تا ۸ ثانیه از یک صدا را به سیستم اضافه کنند. سپس Altered از این نمونه برای شبیهسازی آن صدا در پروژههای بعدی استفاده میکند.
-
تبدیل متن به گفتار (Text-to-Speech Editor): با باز کردن ویرایشگر تبدیل متن به گفتار، کاربر میتواند فیلمنامه خود را آپلود کرده و صدای موردنظر را انتخاب کند. سبکهای روایت با توجه به نوع صدا متغیر هستند. به عنوان مثال، برای برخی صداها امکان انتخاب از میان سبکهایی نظیر "خنثی با تمایل اندک به سردی" تا "شاد و پرانرژی" وجود دارد. نتایج ممکن است با توجه به ترکیب صدا، سبک و فیلمنامه، کاملاً متفاوت یا حتی گاهی غیرمنتظره باشند.
هوش مصنوعی تبدیل متن به گفتار Altered یک ویرایشگر صوتی داخلی نیز ارائه میدهد که امکانات گستردهای از جمله:
- رونویسی خودکار صدا (Transcription)
- تولید گفتار از متن
- حذف نویز و تمیز سازی صوتی.
قیمتگذاری هوش مصنوعی تبدیل متن به صدای Altered
پلن رایگان محدود برای تست اولیه در دسترس است و پلن های پولی از ۶ دلار در ماه آغاز میشوند.
6. Murf: بهترین مولد صدای هوش مصنوعی برای کنترل لحن و تاکید در گفتار (Emphasis Control)

تصویر(7)
در تولید صوت حرفهای، کنترل تأکید روی واژگان کلیدی یکی از مهمترین عوامل برای ایجاد حس، انتقال دقیق پیام و درک بهتر مخاطب می باشد. این همان چیزی است که Murf AI به صورت مؤثر و کاربردی در اختیار کاربران قرار میدهد، ابزاری که تأکید (Emphasis) را روی تمامی کلمات قابل تنظیم میکند.
برای درک اهمیت این قابلیت، کافی است تمرین سادهای از بازیگری را در ذهن داشته باشید. یک جمله را انتخاب کرده و هر بار یک واژه متفاوت را با تأکید بخوانید. با هر تغییر، معنی و حس جمله تغییر میکند.
در محیط کار با هوش مصنوعی تبدیل متن به صدای Murf، توسط افزودن متن به اولین بلوک پروژه، کنار دکمه پخش، آیکونی شبیه حباب گفتگو ظاهر میگردد. با کلیک روی آن، یک پنجره پاپ آپ نمایان میشود که تمامی کلمات آن بخش را نمایش میدهد. کاربر میتواند با کلیک در نقاط مختلف از محور افقی (ترتیب کلمات) و عمودی (شدت تأکید: پایین، متوسط، بالا)، تأکیدها را برای هر واژه تنظیم کند.
این سطح از دقت روی کنترل تأکید، در میان پلتفرمهای گفتار مصنوعی، کمنظیر است و به خصوص در سناریوهای نمایشی، تبلیغاتی یا آموزشی که لحن و وزن کلمات اهمیت بالایی دارند، کاربردی می باشد.
گذشته از کنترل تأکید، ابزار تولید صدای هوش مصنوعی Murf امکاناتی همچون تنظیم سرعت کلی بیان و زیر و بم صدا، افزودن دستی مکثها و تلفظ سفارشیسازیشده (Custom Pronunciation) را ارائه میدهد.
در بخش پایینی محیط ویرایش، کاربران میتوانند نوار زمانی پروژه را باز کنند و محتوای صوتی را با ویدیو و موسیقی ترکیب کرده و خروجی نهایی را مستقیماً از Murf AI دریافت نمایند. این موضوع Murf را به ابزاری کاربردی برای تولید ویدیوهای کوتاه، تیزر یا محتوای تبلیغاتی تبدیل میکند.
همچنین امکان دعوت اعضای تیم برای همکاری روی پروژهها فراهم است. افراد میتوانند روی بخش های مختلف فیلمنامه نظر بگذارد و در فرآیند تنظیمات گفتار مشارکت کنند که برای پروژههای گروهی ارزشمند است.
با آنکه هوش مصنوعی تبدیل متن به صدای Murf یک پلن رایگان شامل ۱۰ دقیقه تولید صدا و دو پروژه ارائه میدهد اما باید توجه داشت که صداهای حرفهایتر (پولی) از نظر طبیعیبودن، تنوع نحوه بیان و وضوح تلفظ، کیفیت به مراتب بالاتری دارند. اگر قصد استفاده جدی از این پلتفرم را دارید، ارتقاء به پلن پولی در مراحل اولیه توصیه میشود.
قیمتگذاری مولد صدای هوش مصنوعی Murf
- پلن رایگان: شامل ۱۰ دقیقه تولید صدا و ۲ پروژه.
- پلن های پولی: از ۲۳ دلار در ماه (پرداخت سالانه) یا ۲۹ دلار (پرداخت ماهانه) آغاز میشود.
آیا OpenAI یک مدل هوش مصنوعی تبدیل متن به صدا دارد؟
شرکت OpenAI، توسعهدهنده ChatGPT، نیز وارد حوزه تولید صدای هوش مصنوعی شده است. در حال حاضر، تنها روش استفاده از قابلیت تبدیل متن به گفتار (Text-to-Speech) این شرکت، توسط API رسمی آن می باشد که نیازمند دانش فنی برای پیادهسازی و راهاندازی است.
علاوه بر آن، OpenAI یک مدل پیشرفته برای شبیهسازی صدا نیز توسعه داده که بنا بر ادعای خود شرکت، به قدری قدرتمند می باشد که در حال حاضر برای استفاده عمومی منتشر نشده است.
آیا استفاده از صداهای تولیدشده توسط هوش مصنوعی قانونی است؟
در اغلب موارد مجاز است. تمامی پلتفرمهایی که در این فهرست مورد بررسی قرار گرفتهاند، مجموعهای از صداهای آماده ارائه میکنند که با رعایت موارد زیر تولید شدهاند:
- بر اساس دادههای صوتی عمومی تنظیم و پردازش می شوند.
- با رضایت افراد واقعی برای استفاده از صدای آنها مدلسازی شدهاند.
در این چارچوب، استفاده از صداهای هوش مصنوعی قانونی است، مشروط بر آنکه در محدوده شرایط خدمات (Terms of Service) و مجوز پلتفرم مورد استفاده، باقی بماند.
جمع بندی
با استفاده از یک ابزار هوش مصنوعی تبدیل متن به صدا، میتوان فیلمنامهها را به روایتی روان و منسجم تبدیل کرد؛ روایتی که بدون نیاز به انجام دهها برداشت یا استخدام یک تیم تولید حرفهای، آماده استفاده در صدای پسزمینه ویدیوها خواهد بود.
تمامی پلتفرمهای معرفیشده در این فهرست، ابزارها و امکاناتی را برای آزمایش ویژگیها و صداها به کاربران ارائه میدهند. بنابراین پیشنهاد میشود یکی از فیلمنامههای خود را انتخاب کرده و این ابزارها را در عمل امتحان کنید. از آنجا که رابط کاربری و نوع تنظیمات در هر پلتفرم متفاوت می باشد، ضروری است تا مدت زمانی را صرف کنید تا دریابید کدام محیط کاری و قابلیتها برای شما منطقیتر و کارآمدتر هستند.