

امروزه بخش بزرگی از ترافیک اینترنت توسط "خزندگان وب" یا همان Web Crawlers تولید میشود. این ربات ها نرمافزارهای خودکاری هستند که بدون دخالت انسان، به وبسایتها درخواست ارسال میکنند. رفتار هر ربات با توجه به هدفی که دنبال میکند، میتواند تفاوتهای زیادی داشته باشد.
مسدود کردن دسترسی ربات ها در وبسایت، یکی از اقدامات مهم جهت مدیریت ترافیک و حفظ امنیت اطلاعات به شمار میرود. مدیران وبسایت توسط روش های مختلفی مانند فایل .htaccess، robots.txt یا تنظیمات سرور، میتوانند از دسترسی ربات های مخرب جلوگیری کنند. این اقدام علاوه بر بهینهسازی منابع سرور، موجب افزایش سرعت بارگذاری صفحات و بهبود تجربه کاربری نیز خواهد شد.
پیش از پرداختن به مبحث مسدود کردن دسترسی ربات ها، ابتدا مهمترین خزندگان فعال در وب معرفی می شوند.

تصویر(1)
ربات های مهم و متداول در سطح وب
کنترل دسترسی ربات ها نقش مهمی در بهینهسازی و امنیت وبسایت دارد. در این بخش، به معرفی ربات های مهم و پرکاربرد سطح وب پرداخته میشود تا نقش آنها در عملکرد وبسایتها و نحوه مدیریت دسترسیشان مشخص گردد.
- Googlebot: توسعهدهنده این ربات گوگل بوده و به عنوان خزنده اصلی موتور جستجوی گوگل برای ایندکس صفحات وب در حال فعالیت است.
این ربات بهطور مرتب سایتها را بررسی میکند تا تغییرات جدید در محتوای آنها به سرعت درون نتایج جستجوی گوگل بروز شود. Googlebot یکی از مهمترین ربات ها برای نمایش صفحات سایت در نتایج جستجوی گوگل است. این ربات تمامی صفحات وب را جمعآوری نموده و لینکها را دنبال میکند تا اطلاعات جدید بروز شوند.
- Facebookexternalhit: این ربات برای شبکههای اجتماعی فیسبوک و اینستاگرام طراحی شده است. هرگاه لینکی از وبسایت شما در این شبکهها به اشتراک گذاشته شود،Facebookexternalhit وارد سایت خواهد شد و اطلاعاتی همچون عنوان، توضیحات و تصویر را جمعآوری میکند.
- Bingbot: توسعه دهنده این ربات مایکروسافت بوده و به عنوان خزنده موتور جستجوی Bingعمل میکند. این ربات مشابه Googlebot بوده و برای نمایش سایت در نتایج جستجوی Bing ضروری است.
- YandexBot:
- توسعهدهنده: یاندکس (موتور جستجوی روسیه)
- کاربرد: ایندکس و رتبهبندی صفحات وب در یاندکس.
- ویژگیها: این ربات برای کاربران روسیه و کشورهای اروپای شرقی بسیار مهم است.
- Baiduspider
- توسعهدهنده: بایدو (موتور جستجوی چین)
- کاربرد: ایندکس سایتها در موتور جستجوی بایدو.
- ویژگیها: این ربات برای سایتهایی که قصد دارند در بازار چین حضور داشته باشند، بسیار اهمیت دارد.
- DuckDuckBot
- توسعهدهنده: DuckDuckGo
- کاربرد: جمعآوری اطلاعات برای موتور جستجوی DuckDuckGo که بر حفظ حریم خصوصی کاربران تمرکز دارد.
- ویژگیها: برخلاف گوگل، DuckDuckGo هیچگونه اطلاعات شخصی از کاربران را جمعآوری نمیکند.
- Slurp Bot
- توسعهدهنده: یاهو
- کاربرد: ایندکس صفحات وب برای سرویسهای جستجوی یاهو.
- ویژگیها: این ربات فعالیت کمتری دارد اما هنوز در برخی از سرویسهای یاهو به کار میرود.
- Twitterbot
- توسعهدهنده: توییتر یا X کنونی
- کاربرد: مانند Facebookexternalhit، برای پیشنمایش لینکها در X استفاده میشود.
- LinkedInBot
- توسعهدهنده: لینکدین
- کاربرد: جمعآوری اطلاعات متا از صفحات وب بهمنظور نمایش لینکها در شبکه اجتماعی لینکدین.
- Applebot
- توسعهدهنده: اپل
- کاربرد: بهمنظور بهبود نتایج جستجو در سرویسهای Siri و Spotlight اپل طراحی شده است.
- ویژگیها: این ربات روی محتوای وب تمرکز دارد تا کاربران دستگاههای اپل بهترین نتایج جستجو را دریافت کنند.
علاوه بر نمونههای شناختهشده، ربات های دیگری نیز وجود دارند که با اهداف مختلف مانند تبلیغات، مانیتورینگ و حتی حملات اسپم یا DDoS به سایتها دسترسی پیدا میکنند.

تصویر(2)
مسدود کردن دسترسی ربات ها از طریق فایل htaccess.
یکی از روشهای ساده برای مسدود کردن دسترسی ربات ها به سایت، توسط فایل.htaccess است. با این روش میتوانید بر اساس مقدار User-Agent، مشخص کنید که کدام ربات ها اجازه دسترسی به سایت شما را دارند و کدام یک باید مسدود شوند.
برای مسدود کردن یکUser-Agent خاص، کدهای زیر را در فایل .htaccess وب سایت خود قرار دهید:
RewriteEngine on
# مسدود کردن ربات های خاص
RewriteCond %{HTTP_USER_AGENT} "examplebot1" [NC,OR]
RewriteCond %{HTTP_USER_AGENT} " examplebot2" [NC,OR]
RewriteCond %{HTTP_USER_AGENT} " examplebot3" [NC]
# پایان مسدود کردن ربات ها
RewriteRule ^.* - [F,L]
توضیحات:
- RewriteCond %{HTTP_USER_AGENT}: این کد برای بررسی User-Agent درخواستها استفاده میشود.
- [NC]: این ویژگی جهت عدم حساسیت به حروف بزرگ و کوچک است.
- [OR]: این ویژگی برای اعمال چند شرط بهکار میرود و اگر هرکدام از شرایط برقرار شود، دستور اجرا خواهد شد.
- RewriteRule ^.* - [F,L] : این کد باعث میشود که درخواست های ربات های مسدودشده، خطای 403 دریافت کنند.
نحوه شناسایی User-Agent درخواستهای ربات ها
جهت شناسایی User-Agent درخواستهای ارسالشده از سمت ربات ها، در هاست های سی پنل میتوانید به بخش "Visitors" یا "Raw Access" مراجعه کنید. در این بخشها تمامی درخواستهای ارسالشده به سایت قابل بررسی بوده و امکان مشاهده User Agent هر درخواست وجود دارد.
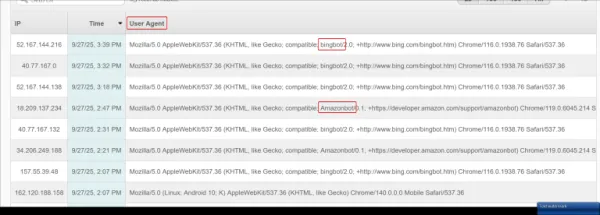
تصویر(3)
اگر ستون User Agent را مشاهده نمی کنید، میتوانید آن را با کلیک روی دکمه بالای صفحه فعال نمایید.
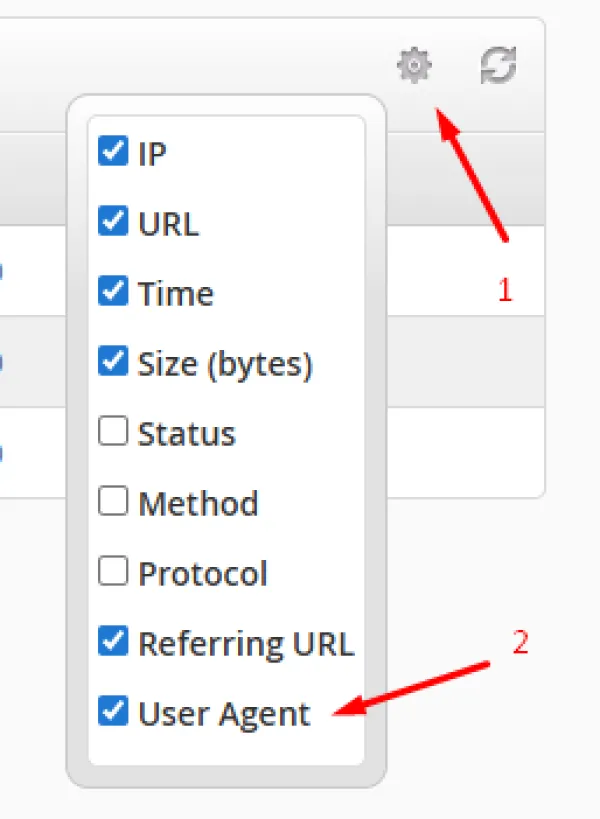
تصویر(4)
مسدود کردن دسترسی ربات ها توسط robots.txt
فایل robots.txt یکی از روشهای متداول برای مدیریت و مسدود کردن دسترسی ربات ها به بخشهای مختلف وبسایت است. مدیران سایت میتوانند با تعریف قوانین مشخص، تعیین کنند که کدام ربات ها به چه مسیرهایی دسترسی داشته یا از آنها منع شوند. این روش ساده، نقش مهمی در کنترل خزش و حفظ منابع سرور ایفا میکند.
نمونه کدهای کاربردی:
User-agent: *
Disallow: /private/
این کد دسترسی تمام ربات ها را به پوشه «private» مسدود میکند.
User-agent: Googlebot
Disallow: /temp/
در این مثال، تنها ربات گوگل از دسترسی به پوشه «temp» منع میشود.
User-agent: *
Disallow: /
این دستور، دسترسی تمامی ربات ها به کل سایت را مسدود میکند.
نحوه درج کد ها در فایل robots.txt
این فایل باید با نام "robots.txt" در ریشه اصلی سایت (Root) قرار گیرد؛ بهعنوان مثال:
https://example.com/robots.txt
پس از ایجاد، قوانین تعریفشده بهصورت خودکار توسط ربات ها بررسی و اعمال میشوند.
جمع بندی
مدیریت و کنترل دسترسی ربات ها به وبسایت از اهمیت بالایی در بهینهسازی عملکرد و حفظ امنیت برخوردار است. با شناخت کراولرهای مختلف و درک نحوه فعالیت آنها، میتوان تصمیمات دقیقتری اتخاذ کرد. همچنین استفاده از روشهایی مانند فایل robots.txtو .htaccess این امکان را فراهم میسازد تا مسدود کردن دسترسی ربات ها بهصورت هدفمند انجام شود و منابع سایت به شکل مؤثرتری مدیریت گردد.